`iGraphMatch`: an R Package for the Analysis of Graph Matching
Source:vignettes/iGraphMatch.Rmd
iGraphMatch.RmdAbstract
iGraphMatch is an R package developed for matching the
corresponding vertices between two edge-correlated graphs. The package
covers three categories of prevalent graph matching algorithms including
relaxation-based, percolation-based, and spectral-based, which are
applicable to matching graphs under the most general settings: weighted
directed graphs of different order and graphs of multiple layers with
auxiliary graph matching techniques. We provide versatile options to
incorporate prior information in the form of seeds with or without noise
and similarity scores. We also implement an S4 class that overloads
popular operations for matrices in R for efficient computation of sparse
plus low-rank matrices, which is a common structure we can decompose the
matrices into in the process of matching graphs. In addition,
iGraphMatch provides functions to summarize the graph
matching results in terms of several evaluation measures and visualize
the matching performance. Finally, the package also enables the users to
sample correlated random graph pairs from classic random graph models to
generate data for simulations. This paper illustrates the practical
applications of the package to the analysis of graph matching by
detailed examples using real data from social networks and
bioinformatics.
Introduction
The graph matching (GM) problem seeks to find an alignment between the vertex sets of graphs that best preserves common structure across graphs. This is often posed as minimizing edge disagreements of two graphs over all alignments. Formally, given \(A\) and \(B\), two adjacency matrices corresponding to two graphs \(G_1=(V_1, E_1)\) and \(G_2=(V_2, E_2)\), the goal is to find \[\begin{align*} \mathop{\mathrm{argmin}}_{P\in\Pi}\lVert A-PBP^T \rVert_F^2 \end{align*}\] where \(\Pi\) is the set of all permutation matrices. GM has wide applications in diverse fields, such as pattern recognition (Berg, Berg, and Malik (2005), Caelli and Kosinov (2004), Conte et al. (2004)), machine learning (Liu and Qiao (2012), Cour, Srinivasan, and Shi (2007)), bioinformatics (Nabieva et al. (2005), Ito et al. (2001)), neuroscience (Chen et al. (2015)), social network analysis (Narayanan and Shmatikov (2009)), and knowledge graph queries (Hu et al. (2018)). More generally, the problem of discovering some true latent alignment between two networks can often be posed as variations on the above problem by adjusting the objective function for the setting.
The well-known graph isomorphism problem is a special case of GM problem when there exists a bijection between the nodes of two graphs which exactly preserves the edge structure. In terms of computational complexity, GM is equivalent to the NP-hard quadratic assignment problem, which is considered a very challenging problem where few theoretical guarantees exist, even in special cases (Finke, Burkard, and Rendl (1987)). For certain problems where the graphs are nearly isomorphic, polynomial-time algorithms do exist (Aflalo, Bronstein, and Kimmel (2015a), Umeyama (1988)) but these methods frequently break down for more challenging instances.
This paper presents the detailed functionality of the
iGraphMatch R package which serves as a practical tool for
the use of prevalent graph matching methodologies. These algorithms
utilize either the spectral embedding of vertices (Umeyama (1988)), or relaxations of the objective
function (Zaslavskiy, Bach, and Vert
(2009), V. Lyzinski et al. (2016)),
or apply ideas from percolation theory (Yartseva
and Grossglauser (2013), Kazemi, Hamed
Hassani, and Grossglauser (2015)). The iGraphMatch
package provides versatile options of working with graphs in the form of
matrices, igraph objects or lists of either, and matching graphs under a
generalized setting: weighted, directed, graphs of a different order,
and multilayer graphs.
In addition, the iGraphMatch package incorporates prior
information: seeds and similarities for all the implemented algorithms.
Seeds, or anchors, refer to partial knowledge of the alignment of two
graphs. In practice, seeds can be users with the same name and location
across different social networks or pairs of genes with the same DNA
sequences. Some algorithms like the percolation algorithm (Yartseva and Grossglauser (2013), Kazemi, Hamed Hassani, and Grossglauser (2015))
which matches two graphs by propagating matching information to
neighboring pairs require seeds to kick off. All algorithms improve
substantially by incorporating seeds and can achieve accurate matching
in polynomial time (Vince Lyzinski, Fishkind, and
Priebe (2014)). Similarity scores are another commonly used prior
which measures the similarity between pairs of nodes across the graphs.
In the bioinformatics area, BLAST similarity score is an example of
similarity scores that plays an important role in aligning two PPI
networks (Singh, Xu, and Berger (2008)).
Similarity scores are usually generated from nodal covariates that are
observed in both networks (Kelley et al.
(2004), Belongie, Malik, and Puzicha
(2002)).
While under many scenarios the availability of exact partial matches, or hard seeding, is not realistic and expensive, the package also enables utilizing noisy prior information. Similarity scores incorporate uncertainty by assigning the pair of nodes with higher similarity scores a bigger chance to match. Seeds with uncertainty and even error can still be handled by self-correcting graph matching algorithms like the Frank-Wolfe algorithm initialized at the noisy partial matching, called soft seeding. Fang, Sussman, and Lyzinski (2018) showed that the Frank-Wolfe algorithm with soft seeding scheme converges quickly to the true alignment under the correlated Erds-R'enyi model with high probability. Thus, the original intractable problem is reduced to be solvable in polynomial time.
Although there exist some open source software and packages
containing graph matching functionality, iGraphMatch
package provides a centralized repository for common graph matching
methodologies with flexibility, tools for developing graph matching
problem methodology, as well as metrics for evaluating and tools for
visualizing matching performance. Among the alternative GM packages, the
most relevant ones include the igraph (Csardi and Nepusz (2006)) package which focuses
on descriptive network analysis and graph visualization based on igraph
objects and provides a single graph matching algorithm, the
GraphM (Zaslavskiy, Bach, and Vert
(2009)) package which implements several GM algorithms proposed
between 1999 and 2009 in C, and the Corbi (Huang, Wu, and Zhang (2013)) R package which is
particularly designed for studies in bioinformatics and
SpecMatch (Mateus et al.
(2008)) which only involves implementations of spectral embedding
based GM algorithms and written in C/C++. None of these packages provide
the breadth of tools, flexibility, and ease-of-use provided by the
iGraphMatch package.
The rest of this paper is organized as follows. Section @ref(sec:background) describes the theoretical representations of the implemented GM algorithms, correlated random graph models and evaluation metrics. Section @ref(sec:usage) discusses the functionality and usage of R functions in the package, illustrated on the synthetic correlated graph pairs. Section @ref(sec:example) presents more complex examples on real data with several functions involved in the analysis and section @ref(sec:conclusion) gives guidelines on using different GM algorithms under different circumstances and concludes the paper.
Graph matching background
In this section, we give background on graph matching and related
problems followed by descriptions of the principal algorithms
implemented in iGraphMatch. For simplicity, we state all
the algorithms in the context of matching undirected, unweighted graphs
with the same cardinality. All algorithms can also be directly applied
to directed and weighted graphs. In the second subsection, we discuss
the techniques for matching graphs with a different number of vertices
along with other extensions. To conclude the section, we introduce the
statistical models for correlated networks and discuss measures for the
goodness of matching.
For the remainder of this paper we use the following notation. Let
\(G_1=(V_1,E_1)\) and \(G_2=(V_2,E_2)\) denote two graphs with
\(n\) vertices. Let \(A\) and \(B\) be their corresponding binary symmetric
adjacency matrices. In the setting of seeded graph matching, suppose
without loss of generality, the first \(s\) pairs of nodes are seeds for
simplicity. In iGraphMatch, much more flexible seed
specifications are possible, which will be illustrated in examples for
usage of the package in section @ref(sec:usage). Accordingly, let \(A\) and \(B\) be partitioned as: \[\begin{equation} \label{eq:seed_blocks}
A=
\begin{bmatrix}
A_{11} & A_{21}^T \\
A_{21} & A_{22}
\end{bmatrix}\text{ and }
B=
\begin{bmatrix}
B_{11} & B_{21}^T \\
B_{21} & B_{22}
\end{bmatrix}
\end{equation}\] where \(A_{11},
B_{11}\in\{0, 1\}^{s\times s}\) denote seed-to-seed adjacencies,
\(A_{21}, B_{21}\in\{0, 1\}^{(n-s)\times
s}\) denote nonseed-to-seed adjacencies and \(A_{22}, B_{22}\in\{0, 1\}^{(n-s)\times
(n-s)}\) denote nonseed-to-nonseed adjacencies. Let \(S\) be an \(n\)-by-\(n\) real-valued matrix of similarity
scores. Let \(\Pi\) be the set of all
permutation matrices and \(\mathcal{D}\) be the set of all doubly
stochastic matrices.
Assignment problems
Matching or assignment problems are core problems in combinatorial optimization and appear in numerous fields (Burkard, Dell’Amico, and Martello (2009)). As we illustrate in Eq. \(\eqref{eq:ob_func}\), a general version of the graph matching problem is equivalent to the quadratic assignment problem (QAP). Similarly, QAP is related to the linear assignment problem (LAP) which also plays a role in GM. The LAP asks how to assign \(n\) items (eg. workers or nodes in \(G_1\)) to \(n\) other items (eg. tasks or nodes in \(G_2\)) with minimum cost. Let \(C\) denote an \({n\times n}\) cost matrix, where \(C_{ij}\) denotes the cost of matching \(i\) to \(j\), then the LAP is to find \[\begin{equation} \label{eq:LAP} \begin{aligned} & \mathop{\mathrm{argmin}}_{P\in \Pi} & \mathrm{trace}(C^TP) \end{aligned} \end{equation}\] LAP is solvable in \(O(n^3)\) time and there are numerous exact and approximate methods for both general (Jonker and Volgenant (1988), Kuhn (1955)) and special cases, such as sparse cost matrices (Volgenant (1996)).
The statement of QAP resembles LAP, except that the cost function is expressed as a quadratic function. Given two \(n\text{-by-}n\) matrices \(A\) and \(B\) which can represent flows between facilities and the distance between locations respectively, or the adjacency matrices of two unaligned graphs, the objective function for QAP is: \[\begin{equation}\label{eq:qap} \mathop{\mathrm{argmin}}_{P\in \Pi} \mathrm{trace}(APBP^T). \end{equation}\] This problem is NP-hard (Finke, Burkard, and Rendl (1987)) leading to a core challenge for any graph matching approach.
As will be illustrated in the rest of the section, some matching algorithms reduce the graph matching problem to solving a LAP. For these algorithms, we include similarity scores \(S\) by adding an additional term \(\mathrm{trace}(S^TP)\) to the reduced objective function.
Graph matching algorithms
In the iGraphMatch package, we implement three types of
prevalent GM algorithms. The first group uses relaxations of the
objective function, including convex, concave, and indefinite
relaxations. The second group consists of algorithms that apply ideas
from percolation theory, where matching information is spread from an
initial set of matched nodes. The last group is based on the spectral
embedding of vertices.
Relaxation-based algorithms
These approaches relax the constraint that \(P\) is a permutation matrix to require only that \(P\) is doubly stochastic, optimizing over \(\mathcal{D}\), the convex hull of \(\Pi\). When \(P\) is a permutation matrix \[\begin{equation} \label{eq:ob_func} \lVert A-PBP^T \rVert_F^2 = \lVert AP-PB \rVert_F^2 = \lVert A \rVert_F^2 + \lVert B \rVert_F^2 - 2\cdot \mathrm{trace}APBP^T. \end{equation}\] However, these equalities do not hold for all \(P\in \mathcal{D}\), leading to different relaxations.
The second term of Eq.\(\eqref{eq:ob_func}\) is a convex function and optimizing it over \(P\in\mathcal{D}\) gives the convex relaxation, where the gradient at \(P\) to the convex relaxed objective function is \(-4 APB + 2A^TAP + 2PBB^T\). The last equality in Eq. \(\eqref{eq:ob_func}\) shows that minimizing edge disagreements is equivalent to maximizing the number of edge agreements, \(\mathrm{trace} APBP^T\), a QAP. Optimizing the indefinite function over \(\mathcal{D}\) gives the indefinite relaxation with gradient \(-2APB\) (V. Lyzinski et al. (2016)).
| Relaxation | Objective Function | Domain | GM Algorithm | Optimization Guarantee | Optimum Form |
|---|---|---|---|---|---|
| None | \(\lVert A-PBP^T \rVert_F^2\) | \(\Pi\) | NA | \(\Pi\) | |
| Indefinite | \(\mathrm{tr}ADBD^T\) | \(\mathcal{D}\) | FW | Local | \(\mathcal{D}\) (often \(\Pi\)) |
| Convex | \(\lVert AD-DB \rVert_F^2\) | \(\mathcal{D}\) | FW, PATH | Global | \(\mathcal{D}\) |
| Concave | \(-\mathrm{tr}(\Delta D)-2\mathrm{tr}(L_1^T D L_2 D^T)\) | \(\mathcal{D}\) | PATH | Local | \(\Pi\) |
Generally, the convex relaxation leads to a solution that is not guaranteed to be near the solution to the original GM. However, Aflalo, Bronstein, and Kimmel (2015a) introduced the class of “friendly” graphs based on the spectral properties of the adjacency matrices to characterize the applicability of the convex relaxation. Matching two friendly graphs by using the convex relaxation is guaranteed to find the exact solution to the GM problem. Unfortunately, this class is quite limiting and does not hold for most statistical models or real-world examples.
Another relaxation is the concave relaxation used in the PATH algorithm (Zaslavskiy, Bach, and Vert (2009)). The concave relaxation uses the Laplacian matrix defined as \(L=D-A\), where \(D\) is the diagonal degree matrix with diagonal entries \(D_{ii}=\sum_{i=1}^N A_{ij}\). Assume \(L_i\) and \(D_i\), \(i=1,2\), are the Laplacian matrices and degree matrices for \(G_1\) and \(G_2\) respectively, then we can rewrite the objective function as \[\begin{equation} \label{eq:concave} \begin{split} \lVert A-PBP^T\rVert_F^2 & = \lVert AP-PB \rVert_F^2\\ & = \lVert (D_1P-PD_2)-(L_1P-PL_2)\rVert_F^2\\ & = -\mathrm{trace}(\Delta P)+\mathrm{trace}(L_1^2)+\mathrm{trace}(L_2^2)-2\mathrm{trace}(L_1^T P L_2 P^T), \end{split} \end{equation}\] where the matrix \(\Delta_{ij}=(D_{2_{jj}}-D_{1_{ii}})^2\). Dropping the terms not dependent on \(P\) in equation \(\ref{eq:concave}\), we obtain the concave function \(-\mathrm{trace}(\Delta P)-2\mathrm{trace}(L_1^T P L_2 P^T)\) on \(\mathcal{D}\).
A summary of the different relaxations is provided in Table \(\ref{tab:relaxation}\). Relaxing the discrete problem to a continuous problem breaks the equivalence to the original formulation of the edge disagreement and enables employing algorithms based on gradient descent.
Frank Wolfe methodology
V. Lyzinski et al. (2016) introduced an algorithm for the relaxed graph matching problem, with each iteration computable in polynomial time, that can find local optima for the relaxations above. The <span style=“font-variant:small-caps;”>Frank-Wolfe (FW) (Frank and Wolfe (1956)) methodology is an iterative gradient ascent approach composed of two steps. The first step finds an ascent direction that maximizes the gradient ascent. In this case the ascent direction is a permutation matrix which is a vertex of the polytope of doubly stochastic matrices. For the convex, indefinite, and concave relaxations, this corresponds to a LAP with the gradient as the cost function. The second step performs a line search along the ascent direction to optimize the relaxed objective function. As the objectives are all quadratic, this line search is simply requires optimizing a single-variable quadratic function along a line segment. After the iterative algorithm converges, the final step of the procedure is to project the doubly stochastic matrix back to the set of permutation matrices, which is also a LAP.
The various relaxed forms can all serve as the objective function \(f(\cdot)\) in the FW Methodology, but in all cases a matrix \(D^0\in \mathcal{D}\) must be chosen to initialize the procedure. For the convex relaxation, the FW methodology is guaranteed to converge to the global optimum regardless of the \(D^0\). On the other hand, the FW algorithm for the indefinite relaxation is not guaranteed to find a global optimum so the initialization is critical.
In many instances, the optimal solution to the convex relaxation lies in the interior of \(\mathcal{D}\). This can lead to inaccurate solutions after the last projection step. The local optima for the indefinite relaxation are often at extreme points of \(\mathcal{D}\), meaning the final projection often does nothing.
The default initialization for the indefinite problem is at the barycenter matrix, \(D^0 = \frac{1}{n}11^T\), but many other initialization procedures can be used. These include randomized initializations, initializations based on similarity matrices, and initializing the indefinite relaxation at the interior point solution of the convex relaxation (Aflalo, Bronstein, and Kimmel (2015b)). When prior information regarding a partial correspondence is known to be noisy, rather than incorporating this information as seeds, one can incorporate it as “soft” seeds which are used to generate the initialization (Fang, Sussman, and Lyzinski (2018)).
When prior information is available in the form of seeds, the seeded graph matching problem (Vince Lyzinski, Fishkind, and Priebe (2014)) works on the objective function \(\ref{eq:ob_func}\) with the permutation matrix \(P^{n\times n}\) substituted by \(I_s\oplus P^{(n-s)\times (n-s)}\), the direct sum of an \(s\times s\) identity matrix and an \((n-s)\times (n-s)\) permutation matrix.
Employing the indefinite relaxed objective function incorporating seeds, we formulate the problem as finding \[\begin{align*} \hat{P} % &= \argmin_{P\in \Pi} \mathrm{trace} A(I_s\oplus P)B(I_s\oplus P)^T \\ &= \mathop{\mathrm{argmax}}_{P\in\mathcal{D}} 2\cdot\mathrm{trace}P^TA_{21}B_{21}^T+\mathrm{trace}A_{22}PB_{22}P^T \end{align*}\] where the gradient to the objective function is \[\begin{equation} \label{eq:sgm_gradient} \nabla f(P)=2\cdot A_{21}B_{21}^T+2\cdot A_{22}PB_{22}. \end{equation}\]
In total, this uses the information between seeded nodes and nonseeded nodes and the nonseed-to-nonseed information. Applying seeded graph matching to the convex relaxation and concave relaxation closely resembles the case of indefinite relaxation.
PATH algorithm
Zaslavskiy, Bach, and Vert (2009) introduced a convex-concave programming approach to approximately solve the graph matching problem. The concave relaxation has the same solution as the original graph matching problem. The PATH algorithm finds a local optimum to the concave relaxation by considering convex combinations of the convex relaxation \(F_0(P)\) and the concave relaxation \(F_1(P)\) denoted by \(F_{\lambda} =(1 - \lambda) F_0 + \lambda F_1\). Starting from the solution to the convex relaxation (\(\lambda=0\)) the algorithm iteratively performs gradient ascent using the FW methodology at \(F_\lambda\), increasing \(\lambda\) after each iteration, until \(\lambda = 1\).
Percolation-based algorithms
Under the FW methodology, all the nodes admit a correspondence but the (relaxed) matching correspondence evolves through iterations. On the other hand, percolation approaches start with a set of seeds, adding one new match at each iteration. The new matches are fixed and hence not updated in future iterations.
Each iteration expands the set of matched nodes by propagating the current matching information to neighbors. The guiding intuition is that more matched neighbors are an indicator of a more plausible match, an intuition analogous to the gradient ascent approaches above. We will present two algorithms in this category where the ExpandWhenStuck algorithm is an extension to the Percolation algorithm.
There are some distinctions about the inputs and outputs of percolation methods compared to the above relaxation methods.
Percolation Algorithm
Yartseva and Grossglauser (2013) provides a simple and fast approach to solve the graph matching problem by starting with a handful of seeds and propagating to the rest of the graphs. At each iteration, the matching information up to the current iteration is encoded in a subpermutation matrix \(P\) where \(P_{ij}=1\) if \(i\) is matched to \(j\), and \(0\) otherwise.
The Percolation algorithm searches for the most promising new match among the unmatched pairs through the mark matrix, \(M=APB\), which is the gradient of the indefinite relaxation when extended to sub-doubly stochastic matrices. When similarity scores are available, they are added to the mark matrix to combine topological structure and similarity scores.
Adopting analogous partitions on the adjacency matrices as in equation \(\eqref{eq:seed_blocks}\), we let \(A_{21}, B_{21}\) denote sub-matrix corresponding to potential adjacencies between unmatched and matched nodes. Since all the candidates of matched pairs are permanently removed from consideration, we need only consider \(M'=A_{21}B_{21}^T\), the sub-matrix of \(M\) corresponding to the unmatched nodes in both graphs. As a result, the Percolation algorithm only uses matched-to-unmatched information to generate new matches.
Moreover, the mark matrix \(M\) can
also be interpreted as encoding the number of matched neighboring pairs
for each pair of nodes \(i\in V_1\),
\(j\in V_2\). Suppose \(u, u'\in V_1\), \(v,v'\in V_2\), \([u,u']\in E_1\) and \([v,v']\in E_2\), then \((u',v')\) is a neighboring pair of
\((u,v)\). In each iteration, while
there remain unmatched nodes with more than \(r\) matched neighboring pairs, the
percolation algorithm matches the pair of nodes with the highest score
\(M_{uv}\),
and adds one mark to all the neighboring pairs of \((u,v)\). Note that the algorithm may stop
before all nodes are matched, leading to the return of a partial
match.
There is only one tuning parameter in the Percolation algorithm, the threshold \(r\) which controls a tradeoff between quantity of matches and quality of matches. With a small threshold, the algorithm has a larger chance of matching wrong pairs. If \(r\) is larger, then the algorithm might stop before matching many pairs (Kazemi, Hamed Hassani, and Grossglauser (2015)).
The Percolation algorithm can be generalized to matching weighted graphs by making an adjustment to how we measure the matching information from the neighbors. Since we prefer to match edges with smaller weight differences and higher absolute weights, we propose to adopt the following update formula for the score associated with each pair of nodes \((i,j)\): \[M_{ij}=M_{ij} + \sum_{u\in N(i)}\sum_{v\in N(j)}1-\frac{|w_{iu}-w_{jv}|}{\max(|w_{iu}|, |w_{jv}|)}.\] Thus, the score contributed by each neighboring pair of \((i,j)\) is a number in \([0,1]\).
ExpandWhenStuck Algorithm
Kazemi, Hamed Hassani, and Grossglauser (2015) extends the Percolation algorithm to a version that can operate with a smaller number of seeds. Without enough seeds, when there are no more unmatched pairs with a score higher or equal to the threshold \(r\), the Percolation algorithm would stop even if there are still unmatched pairs. ExpandWhenStuck uses all pairs of nodes with at least one matched neighboring pair, \(M_{ij}\geq 1\), as new seeds to restart the matching process by adding one mark to all of the new seeds’ neighboring pairs, without updating the matched set. If the updated mark matrix consists of new pairs with marks greater or equal to \(r\), then the percolation algorithm continues, leading to larger matched sets.
Spectral-based algorithm
Another class of graph matching algorithms uses the spectral properties of adjacency matrices.
IsoRank Algorithm
Singh, Xu, and Berger (2008) propose the IsoRank algorithm that uses neighboring topology and similarity scores and exploits spectral properties of the solution. The IsoRank algorithm is also based on the relaxation-based algorithms by encoding the topological structure of two graphs in \(ADB\), which is again proportional to the gradient of the indefinite relaxation. However, the representations of each term of \(ADB\) are slightly different. \(A\) and \(B\) are the column-wise normalized adjacency matrices and \(D\) is not necessarily a doubly stochastic matrix yet \(D_{ij}\) still indicates how promising it is to match \(i\in V_1\) to \(j\in V_2\).
Similar to the idea of Percolation algorithm, the intuition is that the impact of a pair of matched nodes is evenly distributed to all of their neighbors to propagate plausible matches. This is achieved by solving the eigenvalue problem \[\begin{align}\label{eq:Iso1} \mathrm{vec}(D)=(A\otimes B) \mathrm{vec}(D), \end{align}\] where \(\mathrm{vec}(D)\) denotes the vectorization of matrix \(D\), and the right hand side is equivalent to \(ADB\).
To combine network-topological structure and similarity scores in the objective function, the normalized similarity score \(E\) is added to the right hand side of Eq. \(\ref{eq:Iso1}\), where \(E=S/\|S\|_1\), and \(|\cdot|_1\) denotes the L1 norm.
Note that when similarity score is not available as prior information, we can also construct a doubly stochastic similarity score matrix from seeds by taking \(I_{s\times s}\oplus \frac{1}{n-s}11_{(n-s)\times (n-s)}\). To solve the eigenvalue problem \(\ref{eq:Iso1}\), we resort to the power method. Finally, the global alignment is generated by a greedy algorithm or using the algorithms for solving the linear assignment problem (LAP).
Umeyama algorithm
Umeyama (1988) is a spectral approach to find approximate solutions to the graph matching problem. Assuming eigendecompositions of adjacency matrices \(A\) and \(B\) as \(A=U_A\Lambda_AU_A^T\) and \(B=U_B\Lambda_BU_B^T\), let \(|U_A|\) and \(|U_B|\) be matrices which takes absolute values of each element of \(U_A\) and \(U_B\). Such modification to the eigenvector matrices guarantees the uniqueness of eigenvector selection. The global mapping is obtained by minimizing the differences between matched rows of \(U_A\) and \(U_B\): \[\begin{align*} \hat{P}=\mathop{\mathop{\mathrm{argmin}}}_{P\in\Pi}\lVert |U_A|-P|U_B|\rVert_F=\mathop{\mathop{\mathrm{argmax}}}_{P\in\Pi}\mathrm{trace}(|U_B||U_A|^TP) \end{align*}\]
The Umeyama algorithm can be generalized to matching directed graphs by eigendecomposing the Hermitian matrices \(E_A\) and \(E_B\) derived from the asymmetric adjacency matrices of the directed graphs. The Hermitian matrix for the adjacency matrix \(A\) is defined as \(E_A=A_S+iA_N\), where \(A_S=(A+A^T)/2\) is a symmetric matrix, \(A_N=(A-A^T)/2\) is a skew-symmetric matrix and \(i\) is the imaginary unit. Similarly, we can define the Hermitian matrix for \(B\). Assume the eigendecompositions of \(E_A\) and \(E_B\) as follows: \[\begin{align*} E_A=W_A\Gamma_AW_A^*, \quad E_B=W_B\Gamma_BW_B^* \end{align*}\] and we aim at searching for: \[\begin{align*} \hat{P}=\mathop{\mathop{\mathrm{argmax}}}_{P\in\Pi}\mathrm{trace}(|W_B||W_A|^TP) \end{align*}\] Note that the Umeyama algorithm works on the condition that two graphs are isomorphic or nearly isomorphic.
Auxiliary graph matching tools
Centering technique
Instead of encoding the non-adjacencies by zeros in the adjacency matrices, the centering technique (Sussman et al. (2018)) assigns negative values to such edges. The first approach is encoding non-adjacent node-pairs as \(-1\) with centered adjacency matrices \(\tilde{A}=2A-\textbf{J}\) and \(\tilde{B}=2B-\textbf{J}\), where \(\textbf{J}\) is a matrix of all ones. An alternative approach relies on modeling assumptions where the pair of graphs are correlated but do not share a global structure. We match \(\tilde{A} = A-\Lambda_A\) and \(\tilde{B} = B-\Lambda_B\), where \(\Lambda\) is an \(n\text{-by-}n\) matrix with \(ij\)-th entry denoting an estimated marginal probability of an edge. In general, \(\Lambda\) is unknown but there are methods in the literature to estimate \(\Lambda\).
Matching centered graphs changes the rewards for matching edges, non-edges, and the penalties for mismatches. Adapting the centering technique for the problem at hand can be used to find specific types of correspondences. This can also be combined with constructing multilayer networks out of single layer networks to match according to multiple criteria (Li and Sussman (2019), Fan et al. (2020)). The centering technique can be applied to any of the implemented graph matching algorithm. It is especially useful when padding graphs with differing numbers of vertices to distinguish isolated vertices from padded vertices.
Padding graphs of different orders
Until this section, we have been considering matching two graphs whose vertex sets are of the same cardinality. However, matching graphs with different orders are commonly seen in real-world problems.
Suppose \(A\in\{0,1\}^{n\times n}\)
and \(B\in\{0,1\}^{n_c\times n_c}\)
with \(n_c<n\). One can then pad the
smaller graph with extra vertices to match the order of the larger
graph, \(\tilde{B}=B\oplus
\textbf{0}_{n-n_c}\) and match \(A\) and \(\tilde{B}\). Every implemented graph
matching algorithm in the iGraphMatch package automatically
handles input graphs with a different number of vertices using sparse
padding with minimal memory impact.
Since the isolated vertices and the padded vertices share the same topological structure, it can be useful to center the original graphs first then pad the smaller graph in the same manner. This approach serves to differentiate between isolated vertices the padded ones. It’s theoretically verified that in the correlated graph model, the centered padding scheme is guaranteed to find the true correspondence between the nodes of \(G_1\) and the induced subgraph of \(G_2\) under mild conditions even if \(|V_1|\ll|V_2|\), but the true alignment is not guaranteed without centering (Sussman et al. (2018)).
Exploiting sparse and low-rank structure
Many real-world graphs, especially large graphs, are often very
sparse with \(o(n^2)\) and often \(\theta(n)\) edges. This can increase the
difficulty of the graph matching problem due to the fact that there are
fewer potential edges to match, but sparse graphs also come with
computational advantages. We rely on igraph and
Matrix for efficient storage of these structures as well as
the efficient implementation of various matrix operations. We also use
the LAPMOD algorithm for sparse LAP problems (Volgenant (1996)) (see below).
Similarly, a low-rank structure appears in some of the procedures
including starting at the rank-1 barycenter matrix and the different
centering schemes. Since low-rank matrices are generally not sparse and
visa-versa we implemented the splr S4 class, standing for
sparse plus low-rank matrices. This class inherits from the
Matrix class and includes slots for an \(n\times n\) sparse matrix x
and \(n\times d\) dense matrices
a and b, to represent matrices of the form
x + tcrossprod(a, b). This class implements efficient
methods for matrix multiplication and other operations that exploit the
sparse and low-rank structure of the matrices. Specifically, these
methods often require only \(O(\|x\|_0) +
O(nd)\) storage as opposed to \(O(n^2)\) required for densely stored
matrices, and enjoy analogous computational advantages. While users can
also use these matrices explicitly, most use of them is automatic within
functions such as init_start and center_graph
and the matrices can largely be used interchangeably with other
matrices.
LAP methods
Multiple graph matching methods include solving an LAP and so we have
included multiple methods for solving LAPs into the package.
Specifically we implement the Jonker-Volgenant algorithm (Jonker and Volgenant (1988)) for dense cost
matrices and the LAPMOD algorithm (Volgenant
(1996)) for sparse cost matrices. Both algorithms are implemented
in C to provide improved performance. The LAPMOD approach is typically
advantageous when the number of non-zero entries is less than 50%. We
also depend on the clue package for the
solve_LSAP function which implements the Hungarian
algorithm (Papadimitriou and Steiglitz
(1998)) for solving an LAP. Each of these methods can be used
independently of a specific graph matching method using the
do_lap function.
Multi-layered graph matching
Frequently, networks edges may have categorical attributes and from these categories, we can construct multilayer graphs (Kivelä et al. (2014)), where each layer in the networks contains edges from specific categories. For matching two multilayer graphs, the standard graph matching problem can be extended as \(\sum_{l=1}^{m}\|A^{(l)} - PB^{(l)}P^T\|_F^2\) where \(m\) denotes the number of categories and \(A^{(l)}, B^{(l)}\) are the adjacency matrices for the \(l\)th layers in each graph. Note, we assume that the layers are aligned, so that layer \(l\) corresponds to the same edge-types in both multi-layer networks.
For an igraph object, the function
split_igraph can be used to convert a single object with
categorical edge attributes into a list with each element only
containing the edges with a specific attribute value. The implemented
algorithms can seamlessly match multi-layer graphs, which are encoded as
a list of either igraph objects or matrix-like
objects. We also implemented a matrixlist S4 class that
implements many standard matrix operations so that algorithms can be
easily extended to work with multilayer networks.
Correlated random graph models
The correlated model (V. Lyzinski et al. (2016)) is essential in the theoretical study of graph matching algorithms. In a single graph, each edge is present in the graph independently with probability \(p\). The correlated model provides a joint distribution for a pair of graphs, where each graph is marginally distributed as an graph and corresponding edge-pairs are correlated.
To sample a pair of correlated graphs with edge probability \(p\), and Pearson correlation \(\rho\), we first sample three independent graphs \(G_1\), \(Z_0\) and \(Z_1\) with edge probabilities \(p\), \(p(1-\rho)\) and \(p+\rho(1-p)\) respectively. Let \(G_2 = (Z_1 \cap G_1) \bigcup (Z_0\cap G_1^c)\).
Yartseva and Grossglauser (2013) provide an alternative formulation for the correlated model. First, one samples a single random graph \(G\) with edge probability \(p'\). Conditioned on \(G\), each edge in \(G\) is present independently in \(G_1,G_2\) with probability \(s'\). These two parameterizations are related to each other by the relationship \(s'=p+\rho(1-p)\) and \(p'=p/(p+\rho(1-p))\). The original parameterization is slightly more general because it allows for the possibility of negative correlation.
In addition to homogeneous correlated random graphs, we also implement heterogeneous generalizations of this model. The stochastic block model (Holland, Laskey, and Leinhardt (1983)) and the random dot product graphs (RDPG) model (Young and Scheinerman (2007)) can both be regarded as extensions of the model. The stochastic block model is useful to represent the community structure of graphs by dividing the graph into \(K\) groups. Each node is assigned to a group and the probability of edges is determined by the group memberships of the vertex pair. For the RDPG model, each vertex is assigned a latent position in \(\mathbb{R}^d\) and edge probabilities are given by the inner product between the latent positions of the vertex pair.
For both of these models, we can consider correlated graph-pairs where marginally they arise from one of these models and again corresponding edge pairs are correlated.
Measures for goodness of matching
The ability to assess the quality of the match when ground truth is unavailable is critical for the usage of the matching approaches. There are various topological criteria that can be applied to measure the quality of matching results. At the graph level, the most frequently used structural measures include matching pairs (MP), edge correctness (EC), and the size of the largest common connected subgraph (LCCS) (Kuchaiev and Przulj (2011)). MP counts the number of correctly matched pairs of nodes, thus can only be used when the true alignment is available. Global counts of common edges (CE) and common non-edges (CNE) can be defined as \[\begin{align*} CE=\frac{1}{2}\sum_{i,j}1\{A_{ij}=PBP^T_{ij} =1\}\quad CNE=\frac{1}{2}\sum_{i,j}1\{A_{ij}=PBP^T_{ij} = 0\}, \end{align*}\] along with error counts such extra edges (EE) and missing edges (ME), \[\begin{align*} EE=\frac{1}{2}\sum_{i,j}1\{A_{ij}=0=1 - PBP^T_{ij}\}\quad ME=\frac{1}{2}\sum_{i,j}1\{A_{ij}= 1 = 1 - PBP^T_{ij}\}, \end{align*}\]
EC measures the percentage of correctly aligned edges, that is the fraction CE\(/|E_1|\). The LCCS denotes the largest subset of aligned vertices such that the corresponding induced subgraphs of each graph are connected. Matches with a larger LCCS are often preferable to those with many isolated components.
Another group of criteria measures the goodness of matching at the vertex level. Informally, we aim at testing the hypotheses \[H_0^{(v)}: \text{the vertex } v \text{ is not matched correctly by } P^*, \] \[H_a^{(v)}: \text{the vertex } v \text{ is matched correctly by } P^*\] for each vertex \(v\).
The goal is to address if the permutation matrix found by graph matching algorithm is significantly different from the one sampled from uniformly distributed permutation matrices (Vince Lyzinski and Sussman (2017)). Unfortunately, vertex-level matching criteria have only received limited attention in the literature, however, we include two test statistics to measure fit. The row difference statistic is the L\(_1\)-norm of the difference between \(A\) and \(P^*B{P^*}^T\), namely \[\begin{equation*} T_d(v,P^*):=\Vert A_{v\cdot}-(P^*B{P^*}^T)_{v\cdot}\Vert_1. \end{equation*}\] Intuitively, a correctly matched vertex \(v\) should induce a smaller \(T_d(v,P^*)\), which for unweighted graphs corresponds to the number of edge disagreements induced by matching \(v\). Alternatively, the row correlation statistic is defined as \[\begin{equation*} T_c(v,P^*):=1 - corr(A_{v\cdot},(P^*B{P^*}^T)_{v\cdot}). \end{equation*}\] We expect the empirical correlation between the neighborhoods of \(v\) in \(A\) and \(P^*B{P^*}^T\) to be larger for a correctly matched vertex.
We employ permutation testing ideas to the raw statistics as a normalization across vertices. Let us take the row difference statistic for example. The guiding intuition is that if \(v\) is correctly matched, the number of errors induced by \(P^*\) across the neighborhood of \(v\) in \(A\) and \(B\) (i.e., \(T_d(v, P^*)\)) should be significantly smaller than the number of errors induced by a randomly chosen permutation \(P\) (i.e., \(T_d(v, P)\)).
With this in mind, let \(\mathbb{E}_P\) and \(\mathrm{Var}_P\) denote the conditional expectation and variance of the raw statistic with \(P\) uniformly sampled over all permutation matrices. The normalization is then given by \[\begin{equation*} T_p(v,P^*):=\frac{T(v,P^*)-\mathbb{E}_PT(v,P)}{\sqrt{Var_PT(v,P)}} \end{equation*}\] where \(T(v, P)\) can be either of the two test statistics we introduced earlier.
In addition to measuring match quality, these vertex-wise statistics can also serve as a tool to find which vertices have no valid match in another network, i.e. the vertex entity is present in one network but not the other.
R functions and usage
The R package iGraphMatch offers versatile options for
graph matching and subsequent analysis. Here we describe the usage of
the package including sampling random correlated graph pairs, graph
matching, and evaluating matching results.
Sampling correlated random graph pairs
We first illustrate the usage of functions for sampling correlated random graph pairs. The usage of graph matching will be demonstrated on the graph-pairs sampled using these methods.
Functions of the form sample_correlated_*_pair for
sampling random graph pairs have the common syntax:
sample_correlated_*_pair(n, ***model parameters***,
permutation = 1:n, directed = FALSE, loops = FALSE)The argument n specifies the number of nodes in each
graph, and the default options are to sample a pair of undirected graphs
without self-loop whose true alignment is the identity. The
permutation argument can be used to permute the vertex
labels of the second graph. The model parameters arguments
vary according to different random graph models and typically consist of
parameters for marginal graph distributions and for correlations between
the corresponding edges. The functions each return a named list of two
igraph objects.
For the homogeneous correlated graph model, the model parameters are
p, the global edge probability, and corr, the
Pearson correlation between aligned vertex-pairs. For example, to sample
a pair of graphs with 5 nodes from \(\mathrm{CorrER}(0.5J, 0.7J)\) we run
library(iGraphMatch)
set.seed(1)
cgnp_pair <- sample_correlated_gnp_pair(n = 5, corr = 0.7, p = 0.5)
(cgnp_g1 <- cgnp_pair$graph1)## IGRAPH 71be861 U--- 5 4 -- Erdos-Renyi (gnp) graph
## + attr: name (g/c), type (g/c), loops (g/l), p (g/n)
## + edges from 71be861:
## [1] 1--2 2--3 2--5 3--5
cgnp_g1[]## 5 x 5 sparse Matrix of class "dgCMatrix"
##
## [1,] . 1 . . .
## [2,] 1 . 1 . 1
## [3,] . 1 . . 1
## [4,] . . . . .
## [5,] . 1 1 . .
cgnp_g2 <- cgnp_pair$graph2Since we didn’t obscure the vertex correspondence by assigning a
value to the permutation argument, the underlying true
alignment is the identity.
For the more general heterogeneous correlated graph model, one needs to specify an edge probability matrix and a Pearson correlation matrix. To sample a pair of graphs from the heterogeneous correlated model again with 5 nodes in each graph, and with random edge probabilities and Pearson correlations:
set.seed(123)
p <- matrix(runif(5^2, .5, .8),5)
c <- matrix(runif(5^2, .5, .8),5)
ieg_pair <- sample_correlated_ieg_pair(n = 5, p_mat = p, c_mat = c)Since the default is undirected graphs without self-loops, the
entries of p and c along and below the
diagonal are effectively ignored.
The stochastic block model requires block-to-block edge probabilities
stored in the pref.matrix argument and the
block.sizes argument indicates the size of each block,
along with the Pearson correlation parameter corr. Next, we
sample a pair of graphs from the stochastic block model with two blocks
of size 2 nodes and 3 nodes respectively, within-group edge
probabilities of .7 and .5, across-group edge probability of .001, and
Pearson correlation equal to .5.
pm <- cbind(c(.7, .001), c(.001, .5))
sbm_pair <- sample_correlated_sbm_pair(n = 5, pref.matrix = pm,
block.sizes = c(2,3), corr = 0.5)The iGraphMatch package also provides functions for
sampling a pair of correlated random graphs with junk vertices, i.e
vertices that don’t have true correspondence in the other graph by
specifying the number of overlapping vertices in the argument
ncore or overlapping block sizes in the argument
core.block.sizes.
The iGraphMatch package offers auxiliary tools for
centering graphs to penalize the incorrect matches as well, which is
implemented in the center_graph function with syntax:
center_graph(A, scheme = c(-1, 1), use_splr = TRUE)with the first input being either a matrix-like or igraph object. The
scheme argument specifies the method for centering graphs.
Options include a pair of scalars where the entries of the adjacency
matrix are linearly rescaled so that their minimum is
min(scheme) and their maximum is max(scheme).
Note, scheme = "center" is the same as
scheme = c(-1, 1). Another option is to pass in a single
integer, where the returned value is the adjacency matrix minus its best
rank-scheme approximation. The last argument
use_splr is a boolean indicating whether to return a
splrMatrix object. We use use_splr = FALSE
here to better display the matrices but use_splr = TRUE
will often result in improved performance, especially for large sparse
networks. Here, we center the sampled graph cgnp_g1 using
different schemes:
center_graph(cgnp_g1, scheme = "center", use_splr = FALSE)## 5 x 5 Matrix of class "dgeMatrix"
## [,1] [,2] [,3] [,4] [,5]
## [1,] -1 1 -1 -1 -1
## [2,] 1 -1 1 -1 1
## [3,] -1 1 -1 -1 1
## [4,] -1 -1 -1 -1 -1
## [5,] -1 1 1 -1 -1
center_graph(cgnp_g1, scheme = 2, use_splr = FALSE)## 5 x 5 Matrix of class "dgeMatrix"
## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.207 0.064 -0.093 0 -0.093
## [2,] 0.064 0.020 -0.029 0 -0.029
## [3,] -0.093 -0.029 -0.458 0 0.542
## [4,] 0.000 0.000 0.000 0 0.000
## [5,] -0.093 -0.029 0.542 0 -0.458Users can then use the centered graphs as inputs to the implemented graph matching algorithms, which serve to alter rewards and penalties for common edges, common non-edges, missing edges, and extra edges.
Graph matching methods
The graph matching methods share the same basic syntax:
gm(A, B, seeds = NULL, similarity = NULL, method = "indefinite",
***algorithm parameters***)| Parameter | Type | Description | Functions |
|---|---|---|---|
start |
Matrix or character | Initialization of the start matrix for iterations. | FW, convex |
lap_method |
Character | Method for solving linear assignment problem. | FW, convex, PATH, IsoRank |
max_iter |
Number | Maximum number of iterations. | FW, convex, PATH, IsoRank |
tol |
Number | Tolerance of edge disagreements. | FW, convex, PATH |
r |
Number | Threshold of neighboring pair scores. | percolation |
ExpandWhenStuck |
Boolean |
TRUE if performs ExpandWhenStuck algorithm. |
percolation |
The first two arguments for graph matching algorithms represent two
networks which can be matrices, igraph objects, or two lists of either
form in the case of multi-layer matching. The seeds
argument contains prior information on the known partial correspondence
of two graphs. It can be a vector of logicals or indices if the seed
pairs have the same indices in both graphs. In general, the
seeds argument takes a matrix or a data frame as input with
two columns indicating the indices of seeds in the two graphs
respectively. The similarity parameter is for a matrix of
similarity scores between the two vertex sets, with larger scores
indicating higher similarity. Notably, one should be careful with the
different scales of the graph topological structure and the vertex
similarity information in order to properly address the relative
importance of each part of the information. The method
argument specifies a graph matching algorithm to use, and one can choose
from “indefinite” (default), “convex”, “PATH”, “percolation”, “IsoRank”,
“Umeyama”, or a self-defined graph matching function which enables users
to test out their own algorithms while remaining compatible with the
package. If method is a function, it should take at least
two networks, seeds and similarity scores as arguments. Users can also
include additional arguments if applicable. The self-defined graph
matching function should return an object of the “graphMatch” class with
matching correspondence, sizes of two input graphs, and other matching
details. As an illustrative example, graph_match_rand
defines a new graph matching function which matches by randomly
permuting the vertex label of the second graph using a random seed
rand_seed. We then apply this self-defined GM method to
matching the correlated graphs sampled earlier with a specified random
seed:
graph_match_rand <- function(A, B, seeds = NULL,
similarity = NULL, rand_seed){
totv1 <- nrow(A[[1]])
totv2 <- nrow(B[[1]])
nv <- max(totv1, totv2)
set.seed(rand_seed)
corr <- data.frame(corr_A = 1:nv,
corr_B = c(1:nv)[sample(nv)])
graphMatch(
corr = corr,
nnodes = c(totv1, totv2),
detail = list(
rand_seed = rand_seed
)
)
}
match_rand <- gm(cgnp_g1, cgnp_g2,
method = graph_match_rand, rand_seed = 123)Other arguments vary for different graph matching algorithms with an
overview given in Table \(\ref{tab:gm-alg}\). The start
argument for the FW methodology with
“indefinite” and “convex” relaxations takes any \(nns\text{-by-}nns\) matrix or an
initialization method including “bari”, “rds” or “convex”. These
represent initializing the iterations at a specific matrix, the
barycenter, a random doubly stochastic matrix, or the doubly stochastic
solution from “convex” method on the same graphs, respectively.
Moreover, sometimes we have access to side information on partial
correspondence with uncertainty. If we still treat such prior
information as hard seeds and pass them through the seeds
argument for “indefinite” and “convex” methods, incorrect information
can yield unsatisfactory matching results. Instead, we provide the
option of soft seeding by incorporating the noisy partial correspondence
into the initialization of the start matrix. The core function used for
initializing the start matrix with versatile options is the
init_start function.
Suppose the first two pairs of nodes are hard seeds and another pair of incorrect seed \((3,4)\) is soft seeds:
hard_seeds <- 1:5 <= 2
soft_seeds <- data.frame(seed_A = 3, seed_B = 4)We generate a start matrix incorporating soft seeds initialized at the barycenter:
as.matrix(start_bari <- init_start(start = "bari", nns = 3,
ns = 2, soft_seeds = soft_seeds))## [,1] [,2] [,3]
## [1,] 0.0 1 0.0
## [2,] 0.5 0 0.5
## [3,] 0.5 0 0.5An alternative is to generate a start matrix that is a random doubly stochastic matrix incorporating soft seeds as follow
set.seed(1)
as.matrix(start_rds <- init_start(start = "rds", nns = 3,
ns = 2, soft_seeds = soft_seeds))## [,1] [,2] [,3]
## [1,] 0.00 1 0.00
## [2,] 0.52 0 0.48
## [3,] 0.48 0 0.52Then we can initialize the Frank-Wolfe
iterations at any of the start matrix by specifying the
start parameter.
When there are no soft seeds, we no longer need to initialize the
start matrix by using init_start first. Instead we can
directly assign an initialization method to the start
argument in the gm function:
match_rds <- gm(cgnp_g1, cgnp_g2, seeds = hard_seeds,
method = "indefinite", start = "rds")Below use solution from the convex relaxation as the initialization for the indefinite relaxation.
set.seed(123)
match_convex <- gm(cgnp_g1, cgnp_g2, seeds = hard_seeds,
method = "indefinite", start = "convex")Now let’s match the sampled pair of graphs from the stochastic block model by using Percolation algorithm. Apart from the common arguments for all the graph matching algorithms, Percolation has another argument representing the minimum number of matched neighbors required for matching a new qualified vertex pair. Here we adopt the default value which is 2. Also, at least one of similarity scores and seeds is required for Percolation algorithm to kick off. Let’s utilize the same set of hard seeds and assume there is no available prior information on similarity scores.
sbm_g1 <- sbm_pair$graph1
sbm_g2 <- sbm_pair$graph2
match_perco <- gm(sbm_g1, sbm_g1, seeds = hard_seeds,
method = "percolation", r = 2)
match_perco## gm(A = sbm_g1, B = sbm_g1, seeds = hard_seeds, method = "percolation",
## r = 2)
##
## Match (5 x 5):
## corr_A corr_B
## 1 1 1
## 2 2 2Without enough prior information on partial correspondence, Percolation couldn’t find any qualifying matches. Suppose in addition to the current pair of sampled graphs, the above sampled correlated homogeneous and heterogeneous graphs are different layers of connectivity for the same set of vertices. We can then match the nonseed vertices based on the topological information in all of these three graph layers. To be consistent, let’s still use the Percolation algorithm with threshold equal to 2 and the same set of seeds.
matrix_lA <- list(sbm_g1, ieg_pair$graph1, cgnp_g1)
matrix_lB <- list(sbm_g2, ieg_pair$graph2, cgnp_g2)
match_perco_list <- gm(A = matrix_lA, B = matrix_lB, seeds = hard_seeds,
method = "percolation", r = 2)
match_perco_list## gm(A = matrix_lA, B = matrix_lB, seeds = hard_seeds, method = "percolation",
## r = 2)
##
## Match (5 x 5):
## corr_A corr_B
## 1 1 1
## 2 2 2
## 3 3 3
## 4 4 4
## 5 5 5With the same amount of available prior information, we are now able to match all the nodes correctly.
Finally, we will give an example of matching multi-layers of graphs using IsoRank algorithm. Unlike the other algorithm, similarity scores are required for IsoRank algorithm. Without further information, we adopt the barycenter as the similarity matrix here.
set.seed(1)
sim <- as.matrix(init_start(start = "bari", nns = 5,
soft_seeds = hard_seeds))
match_IsoRank <- gm(A = matrix_lA, B = matrix_lB,
seeds = hard_seeds, similarity = sim,
method = "IsoRank", lap_method = "LAP")Graph matching functions return an object of class “graphMatch” which contains the details of the matching results, including a list of the matching correspondence, a call to the graph matching function and dimensions of the original two graphs.
match_convex@corr## corr_A corr_B
## 1 1 1
## 2 2 2
## 3 3 5
## 4 4 4
## 5 5 3
match_convex@call## gm(A = cgnp_g1, B = cgnp_g2, seeds = hard_seeds, method = "indefinite",
## start = "convex")
match_convex@nnodes## [1] 5 5Additionally, “graphMatch” also returns a list of matching details
corresponding to the specified method. Table \(\ref{tab:gm-value}\) provides an overview
of returned values for different graph matching methods. With the
seeds information, one can obtain a node mapping for
non-seeds accordingly
match_convex[!match_convex$seeds]## corr_A corr_B
## 3 3 5
## 4 4 4
## 5 5 3| Parameter | Description | Functions |
|---|---|---|
seeds |
A vector of logicals indicating if the corresponding vertex is a seed | All the functions |
soft |
The functional similarity score matrix with which one can extract more than one matching candidates | FW, convex, PATH, IsoRank, Umeyama |
lap_method |
Choice for solving the LAP. | FW, convex, Umeyama, IsoRank |
iter |
Number of iterations until convergence or reaches the max_iter. | FW, convex, PATH |
max_iter |
Maximum number of replacing matches. | FW, convex |
match_order |
The order of vertices getting matched. | percolation, IsoRank |
The “graphMatch” class object can also be flexibly used as a matrix. In addition to the returned list of matching correspondence, one can obtain the corresponding permutation matrix in the sparse form.
match_convex[]## 5 x 5 sparse Matrix of class "dgCMatrix"
##
## [1,] 1 . . . .
## [2,] . 1 . . .
## [3,] . . . . 1
## [4,] . . . 1 .
## [5,] . . 1 . .Notably, multiplicity is applicable to the “graphMatch” object directly without converting to the permutation matrix. This enables obtaining the permuted second graph, that is \(PBP^T\) simply by
match_convex %*% cgnp_g2## IGRAPH 3d3c088 UN-- 5 5 -- Erdos-Renyi (gnp) graph
## + attr: name_1 (g/c), name_2 (g/c), type_1 (g/c), type_2 (g/c), loops_1
## | (g/l), loops_2 (g/l), p_1 (g/n), p_2 (g/n), name (g/c), type (g/c),
## | loops (g/l), p (g/n), name (v/n)
## + edges from 3d3c088 (vertex names):
## [1] 5--3 2--5 2--3 1--5 1--2Evaluation of goodness of matching
Along with the graph matching methodology, iGraphMatch
has many capabilities for evaluating and visualizing the matching
performance. After matching two graphs, the function
summary can be used to get a summary of the overall
matching result in terms of commonly used measures including the number
of matches, the number of correct matches, common edges, missing edges,
extra edges and the objective function value. The edge matching
information is stored in a data frame named
edge_match_info. Note that summary outputs the
number of correct matches only when the true correspondence is known by
specifying the true_label argument with a vector indicating
the true correspondence in the second graph. Applying the
summary function on the matching result
match_convex with true_label = 1:5, indicating
the true correspondence is the identity that provides these
summaries.
summary(match_convex, cgnp_g1, cgnp_g2, true_label = 1:5)## Call: gm(A = cgnp_g1, B = cgnp_g2, seeds = hard_seeds, method = "indefinite",
## start = "convex")
##
## # Matches: 3
## # True Matches: 1, # Seeds: 2, # Vertices: 5, 5
##
## common_edges 4.0
## missing_edges 0.0
## extra_edges 1.0
## fnorm 1.4Applying the summary function to a multi-layer graph
matching result returns edge statistics for each layer.
summary(match_IsoRank, matrix_lA, matrix_lB)## Call: gm(A = matrix_lA, B = matrix_lB, seeds = hard_seeds, similarity = sim,
## method = "IsoRank", lap_method = "LAP")
##
## # Matches: 3, # Seeds: 2, # Vertices: 5, 5
## layer 1 2 3
## common_edges 2.0 6.0 4.0
## missing_edges 0.0 1.0 0.0
## extra_edges 1.0 0.0 1.0
## fnorm 1.4 1.4 1.4In realistic scenarios, the true correspondence is not available. As
introduced in section \(\ref{sec:background}\), the user can use
vertex level statistics to evaluate match performance. The
best_matches function evaluates a vertex-level metric and
returns a sorted data.frame of the vertex-matches with the
metrics. The arguments are the two networks, a specific measure to use,
the number of top-ranked vertex-matches to output, and the matching
correspondence in the second graph if applicable. As an example here, we
apply best_matches to rank the matches from above with the
true underlying alignment
best_matches(cgnp_g1, cgnp_g2, match = match_convex,
measure = "row_perm_stat", num = 3,
true_label = 1:igraph::vcount(cgnp_g1))## A_best B_best measure_value precision
## 1 4 4 -1.4 1.00
## 2 3 5 -1.2 0.50
## 3 5 3 -1.2 0.33Note, best_matches uses seed information from the
match parameter and only outputs non-seed matches. Without
the true correspondence, true_label would take the default
value and the output data frame only contains the first three
columns.
To visualize the matches of smaller graphs, the function
plot displays edge discrepancies of the two matched graphs
by an adjacency matrix or a ball-and-stick plot, depending on the input
format of two graphs.
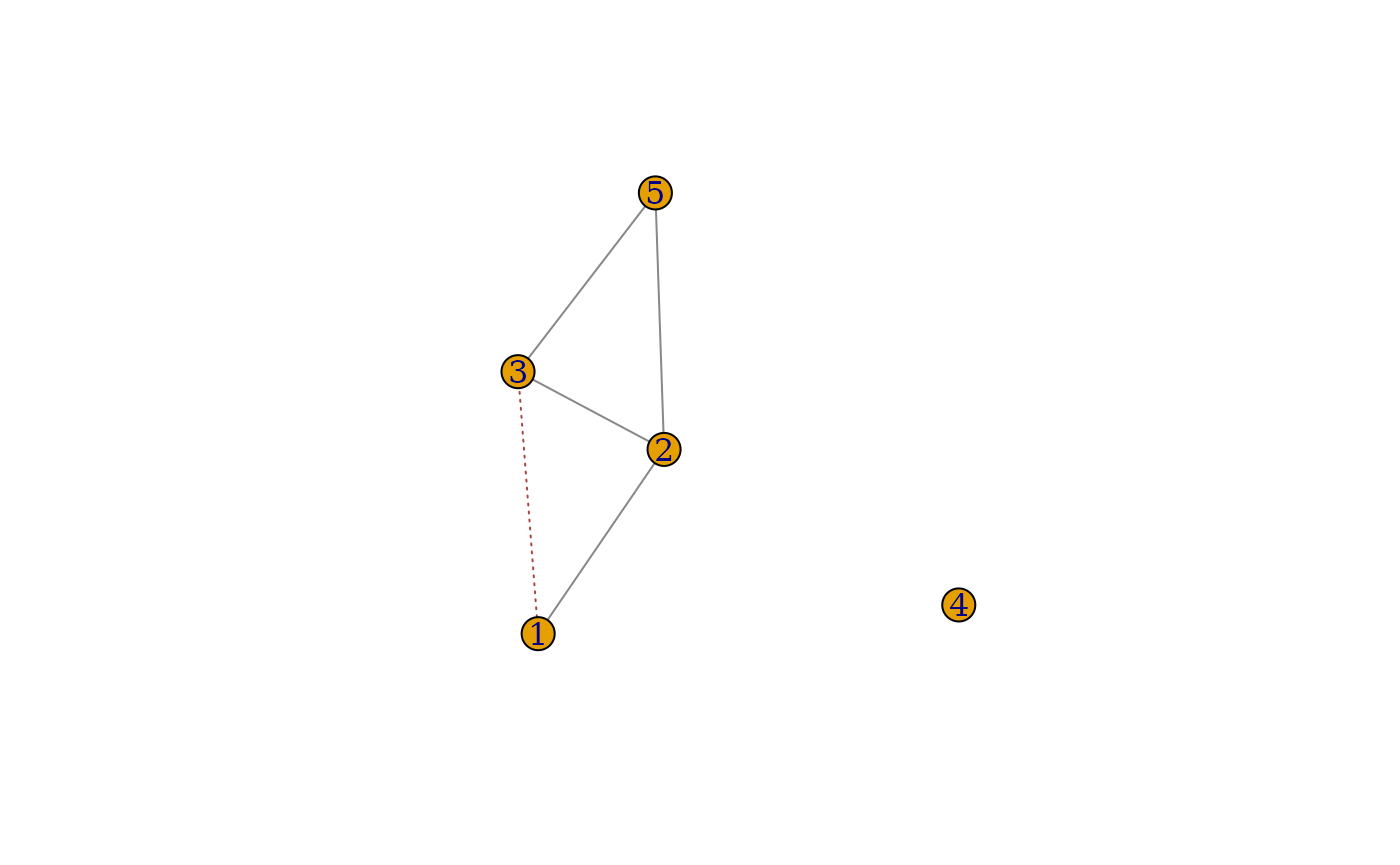
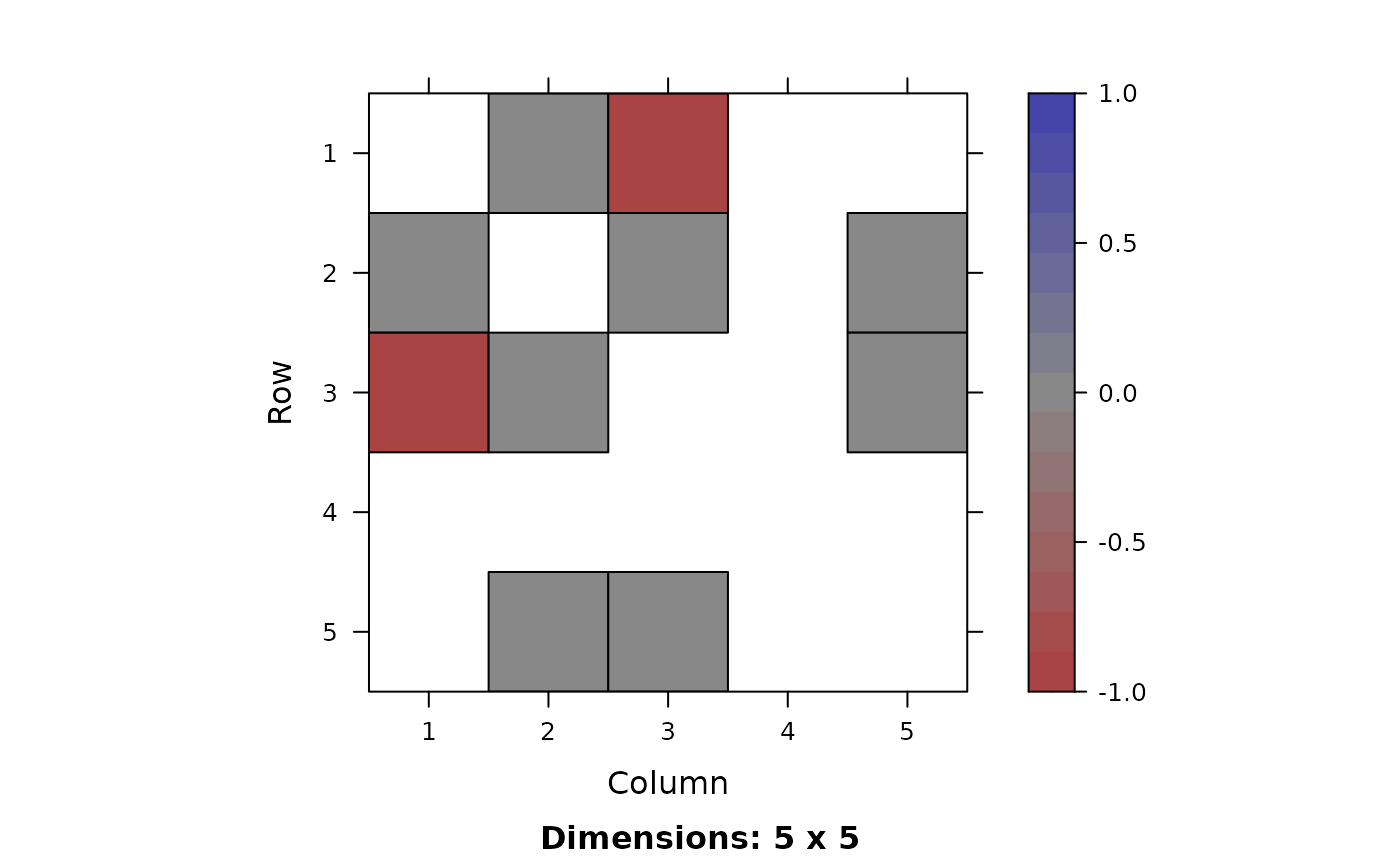
Match visualizations. Grey, blue, and red colors indicate common edges, missing edges present only in the first network, and extra edges present only in the second network, respectively.
The plots for visualizing matching performance of
match_convex are shown in Figure @ref(fig:visualization).
Grey edges and pixels indicate common edges, red ones indicate edges
only in the second graph. If they were present, blue pixels and edges
represent missing edges that only exist in the first graph. The
corresponding linetypes are solid, short dash, and long dash.
Examples
In this section, we demonstrate graph matching analysis using
iGraphMatch via examples on real datasets, including
communication networks, neuronal networks, and transportation networks.
Table @ref(tab:dataset-overview) presents brief overviews of the first
two datasets. Note that the number of edges doesn’t consider weights for
weighted graphs, and for directed graphs, an edge from node \(i\) to node \(j\) and another edge from \(j\) to \(i\) will be counted as two edges. Tables
@ref(tab:edge-summary) and @ref(tab:edge-summary-trans) summarize the
edge correspondence between two graphs under the true alignment
including the number of common edges, missing edges, and extra edges in
two graphs.
In the first Enron email network example, we demonstrate the usage of Frank-Wolfe methodology and how to improve matching performance by using the centering technique and incorporating adaptive seeds. In the second example using C. Elegans synapses networks, we illustrate how to use soft matching for a challenging graph matching task using Frank-Wolfe methodology, PATH algorithm and IsoRank algorithm. Finally, we include an example of matching two multi-layer graphs with similarity scores on the Britain transportation networks.
| Dataset | # Nodes | # Edges | Correlation | Weighted | Directed | Loop |
|---|---|---|---|---|---|---|
| Enron | 184 | 488 / 482 | 0.85 | No | Yes | Yes / Yes |
| C. Elegans | 279 | 2194 / 1031 | 0.10 | Yes | Yes | No / Yes |
| Dataset | Common edges | Missing edges | Extra edges |
|---|---|---|---|
| Enron | 412 | 76 | 70 |
| C. Elegans | 116 | 981 | 400 |
Example: Enron Email Network Data
The Enron email network data was originally made public by the Federal Energy Commission during the investigation into the Enron Corporation (Leskovec et al. (2008)). Each node of Enron network represents an email address and if there is at least one email sent from one address to another address, a directed edge exists between the corresponding nodes.
The iGraphMatch package includes the Enron email network
data in the form of a pair of igraph objects derived from
the original data where each graph represents one week of emails between
184 email addresses. The two networks are unweighted and directed with
edge densities around 0.01 in each graph and the empirical correlation
between two graphs is 0.85.
First, let’s load packages required for the following analysis:
Visualization of Enron networks
We visualize the aligned Enron networks using the function with vertices sorted by a community detection algorithm (Clauset, Newman, and Moore (2004)) and degree. For detailed interpretations to figure @ref(fig:Enron-graph), please refer to figure @ref(fig:visualization).
g <- igraph::as.undirected(Enron[[1]])
com <- igraph::membership(igraph::cluster_fast_greedy(g))
deg <- rowSums(as.matrix(g[]))
ord <- order(max(deg)*com+deg)
plot(Enron[[1]][][ord,ord], Enron[[2]][][ord,ord])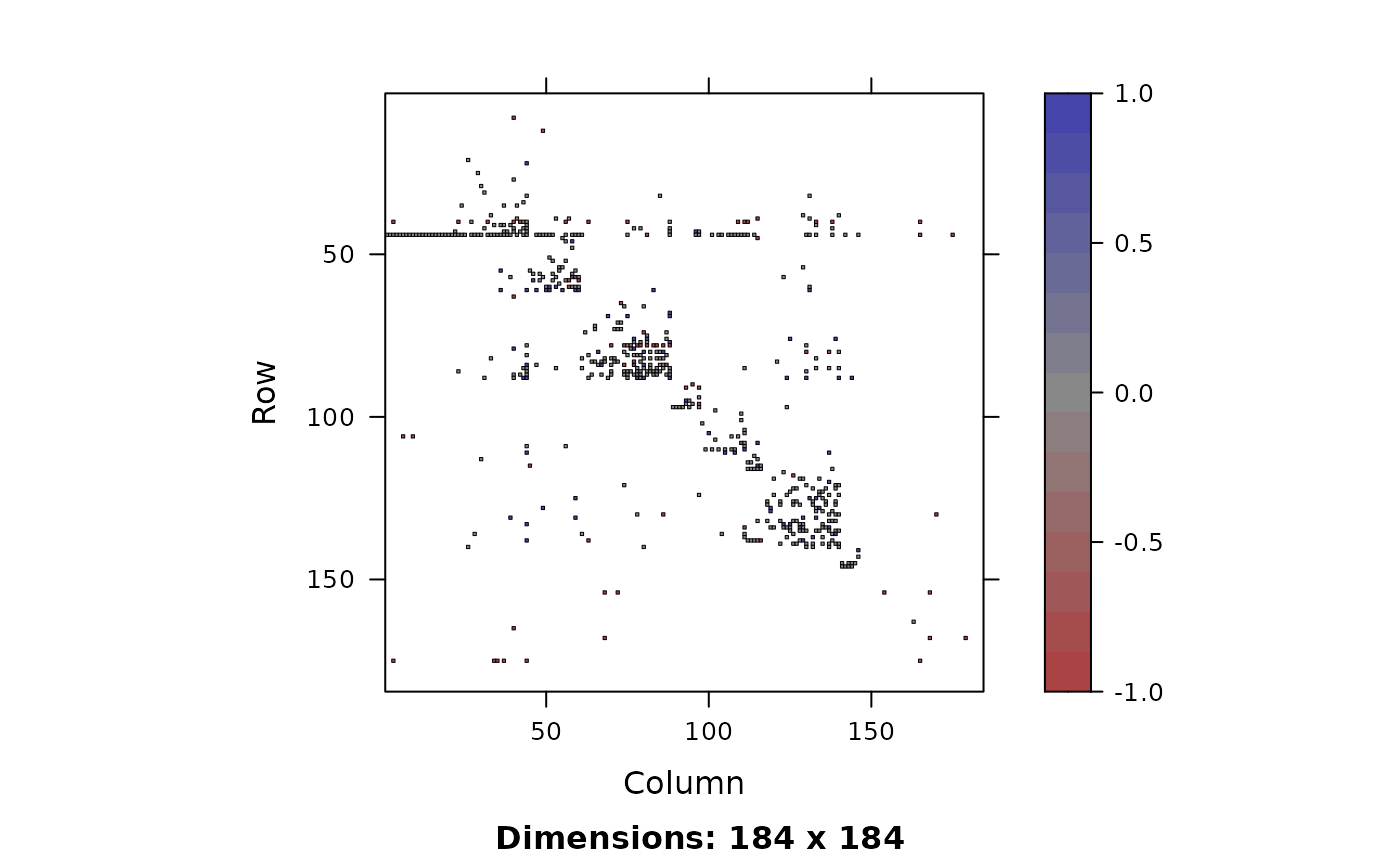
Asymmetric adjacency matrices of aligned Enron Corporation communication networks. The vertices are sorted by a community detection algorithm (Clauset, Newman, and Moore (2004)) and degree.
Note that 37 and 32 out of the total 184 nodes are isolated from the other nodes in two graphs respectively, indicating the corresponding employees haven’t sent or received emails from other employees. This adds difficulty to matching since it’s impossible to distinguish the isolated nodes based on topological structure alone. We first keep only the largest connected component of each graph.
vid1 <- which(largest_cc(Enron[[1]])$keep)
vid2 <- which(largest_cc(Enron[[2]])$keep)
vinsct <- intersect(vid1, vid2)
v1 <- setdiff(vid1, vid2)
v2 <- setdiff(vid2, vid1)
A <- Enron[[1]][][c(vinsct, v1), c(vinsct, v1)]
B <- Enron[[2]][][c(vinsct, v2), c(vinsct, v2)]The sizes of largest connect components of two graphs are 146 and 151, which are different. We reorder two graphs so that the first 145 nodes are aligned and common to both graphs.
Matching largest connected components using FW Algorithm
Let’s assume the Enron email communication network from the second week is anonymous, and we aim at finding an alignment between the email addresses from the first network and the second one to de-anonymize the latter. Additionally, we want to find the email addresses that are active in both months.
Suppose no prior information on partial alignment is available in this example. We match the two largest connected components using the FW algorithm with indefinite relaxation since seeds and similarity scores are not mandatory for this method.
Without any prior information, and arguments take default values which are . For the argument, we assign equal likelihood to all the possible matches by initializing at the barycenter. Since two graphs are of different sizes, the function automatically pads the smaller graph with extra 0’s.
## corr_A corr_B
## 1 1 27
## 2 2 2
## 3 3 30
## 4 4 4
## 5 5 5
## 6 6 6Then, we check the summary of matching performance in terms of matched nodes, matched edges and the graph matching objective function.
summary(match_FW, A, B)## Call: gm(A = A, B = B, start = "bari", max_iter = 200)
##
## # Matches: 151, # Seeds: 0, # Vertices: 146, 151
##
## common_edges 353
## missing_edges 134
## extra_edges 128
## fnorm 16In this example, we can evaluate the matching result based on statistics on matched edges. Without any seeds or similarity scores, around 72% of edges are correctly matched.
Centering the larger graph
We can try to improve performance by centering B by
assigning -1 to non-edges, so that we penalize edges that are missing in
B but present in A.
A_center <- center_graph(A = A, scheme = "naive", use_splr = TRUE)
B_center <- center_graph(A = B, scheme = "center", use_splr = TRUE)
set.seed(1)
match_FW_center <- gm(A = A_center, B = B_center,
start = "bari", max_iter = 200)
summary(match_FW_center, A, B)## Call: gm(A = A_center, B = B_center, start = "bari", max_iter = 200)
##
## # Matches: 151, # Seeds: 0, # Vertices: 146, 151
##
## common_edges 396
## missing_edges 91
## extra_edges 85
## fnorm 13From the summary tables, we would prefer matching Enron networks with the application of the centering scheme, since we get more matched common edges, as well as fewer missing edges and extra edges.
Matching with adaptive seeds
Supposing we have no access to ground truth, we use the function to measure and rank the vertex-wise matching performance. Below shows the 6 matches that minimize the row permutation statistic.
bm <- best_matches(A = A, B = B, match = match_FW_center,
measure = "row_perm_stat")
head(bm)## A_best B_best measure_value
## V83 65 65 -40.6
## V75 57 57 -3.4
## V147 115 115 -3.2
## V59 43 43 -2.9
## V64 48 48 -2.3
## V51 36 36 -1.9Since seeded graph matching enhances the graph matching performance substantially (Vince Lyzinski, Fishkind, and Priebe (2014)), it may be useful to use some of these best matches as seeds to improve matching results. Here, we use adaptive seeds, taking the \(ns\) best matches and using them as seeds in a second run of the matching algorithm. The table below displays edge statistics and objective function values for different number of adaptive seeds used. The second column in the table shows the matching precision of the adaptive seeds based on ground truth. Incorporating adaptive seeds and repeating the FW matching procedure on centered graphs further improve the matching results, compared with the case without any adaptive seeds when \(ns=0\). The first 40 pairs of matched nodes ranked by function are all correctly matched, and this is also when matching is improved the most.
match_w_hard_seeds <- function(ns){
seeds_bm <- head(bm, ns)
precision <- mean(seeds_bm$A_best == seeds_bm$B_best)
match_FW_center_seeds <- gm(A = A_center, B = B_center,
seeds = seeds_bm, similarity = NULL,
start = "bari", max_iter = 100)
edge_info <- summary(match_FW_center_seeds, A, B)$edge_match_info
cbind(ns, precision, edge_info)
}
set.seed(12345)
map_dfr(seq(from = 0, to = 80, by = 20), match_w_hard_seeds)| ns | precision | common | missing | extra | fnorm |
|---|---|---|---|---|---|
| 0 | NaN | 327 | 160 | 154 | 18 |
| 20 | 1.00 | 411 | 76 | 70 | 12 |
| 40 | 0.98 | 407 | 80 | 74 | 12 |
| 60 | 0.90 | 393 | 94 | 88 | 13 |
| 80 | 0.86 | 397 | 90 | 84 | 13 |
As the number of adaptive seeds increases, the precision of adaptive seeds decreases. Note that if they are treated as hard seeds, incorrect matches will remain in the matched set and might cause a cascade of errors. An alternative way is to treat the top-ranked matches as soft seeds embedded in the start matrix to handle the uncertainty. In this way, adaptive seeds not only provide prior information but also evolve over iterations. The table below shows that the soft seeding approach always outperforms or performs as good as the hard seeding approach regardless of the number of adaptive seeds being used.
match_w_soft_seeds <- function(ns){
seeds_bm <- head(bm, ns)
precision <- mean(seeds_bm$A_best == seeds_bm$B_best)
start_soft <- init_start(start = "bari",
nns = max(dim(A)[1], dim(B)[1]),
soft_seeds = seeds_bm)
match_FW_center_soft_seeds <- gm(A = A_center, B = B_center,
start = start_soft, max_iter = 100)
edge_info <- summary(match_FW_center_soft_seeds, A, B)$edge_match_info
cbind(ns, precision, edge_info)
}
set.seed(12345)
map_dfr(seq(from = 0, to = 80, by = 20), match_w_soft_seeds)| ns | precision | common | missing | extra | fnorm |
|---|---|---|---|---|---|
| 0 | NaN | 327 | 160 | 154 | 18 |
| 20 | 1.00 | 410 | 77 | 71 | 12 |
| 40 | 0.98 | 407 | 80 | 74 | 12 |
| 60 | 0.90 | 398 | 89 | 83 | 13 |
| 80 | 0.86 | 398 | 89 | 83 | 13 |
Core vertices detection
The function can also be used to detect core vertices. Suppose the ground truth is known and that the first 145 vertices are core vertices. The mean precision of detecting core vertices and junk vertices using function is displayed in figure \(\ref{fig:core}\). A lower rank is a stronger indicator of a core vertex and a higher rank is a stronger indicator of a junk vertex. Let \(r^C_i, 1\le i\le n_c\) and \(r^J_j, 1\le j\le n_j\) denote the ranks associated with each core vertex and each junk vertex. The figure shows the precision of identifying core vertices at each low rank \(r\), i.e. \(\frac{1}{r}\sum_{i = 1}^{n_c}1_{r^C_i\le r}\), and the precision of identifying junk vertices at each high rank \(r\), i.e. \(\frac{1}{r}\sum_{j = 1}^{n_j}1_{r^J_j\ge n_c+n_j-r}\), which are separated by the vertical lines.
nc <- length(vinsct)
nj <- max(length(v1), length(v2))
core_precision <- 1:nc %>% map_dbl(~mean(bm$A_best[1:.x]<=nc))
junk_precision <- 1:nj %>% map_dbl(~mean(bm$A_best[(nc+.x):(nc+nj)]>nc))Core detection performance is substantially better than chance, as represented by the dotted horizontal lines. The top 88 are all core vertices indicating good overall performance for core identification. For junk identification, the junk vertices are ranked 63, 62, 61, 49, 15, 10 according to which have the lowest score, indicating that some junk vertices are difficult to identify.

Mean precision for identifying core and junk vertices for the Enron networks by using the row permutation test. The vertical lines separate the performance of identifying core vertices with low ranks from junk vertices with high ranks. The horizontal lines indicate the performance of a random classifier.
Example: C. Elegans Network Data
The C. Elegans networks consist of the chemical synapses network and the electrical synapses network of the roundworm, where each of 279 nodes represents a neuron and each edge represents the intensity of synapse connections between two neurons (Chen et al. (2015)). Matching the chemical synapses network to the electrical synapses network is essential for understanding how the brain functions. These networks are quite sparse with edge densities of 0.03 and 0.01 in each graph and the empirical correlation between two graphs is 0.1.
A challenging task
For simplicity, we made the networks unweighted and undirected for the experiments, and we assume the ground truth is known to be the identity.
C1 <- C.Elegans[[1]][] > 0
C2 <- C.Elegans[[2]][] > 0
plot(C1[], C2[])
match <- gm(C1, C2, start = Matrix::Diagonal(nrow(C1)))
plot(C1[], C2[], match)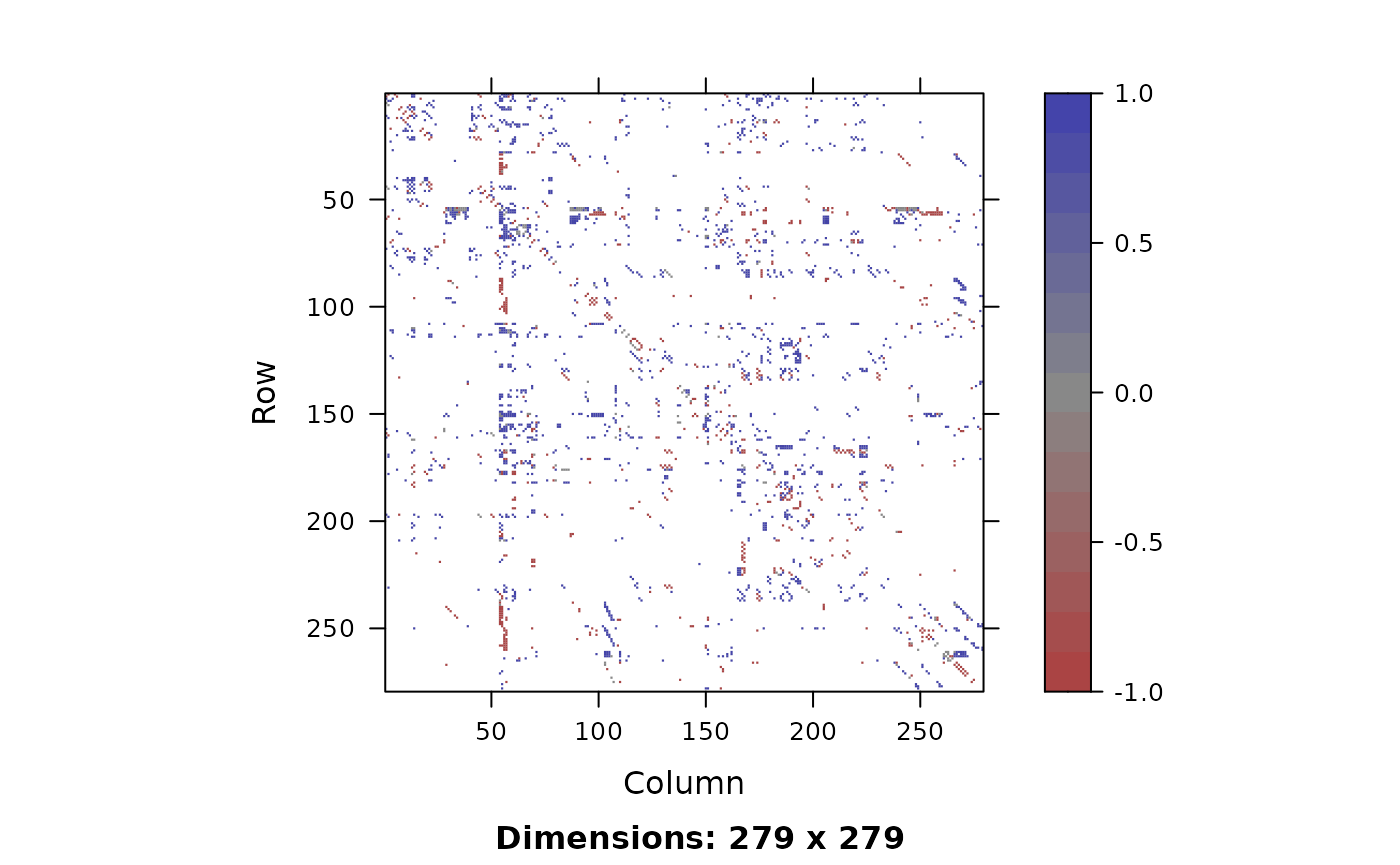
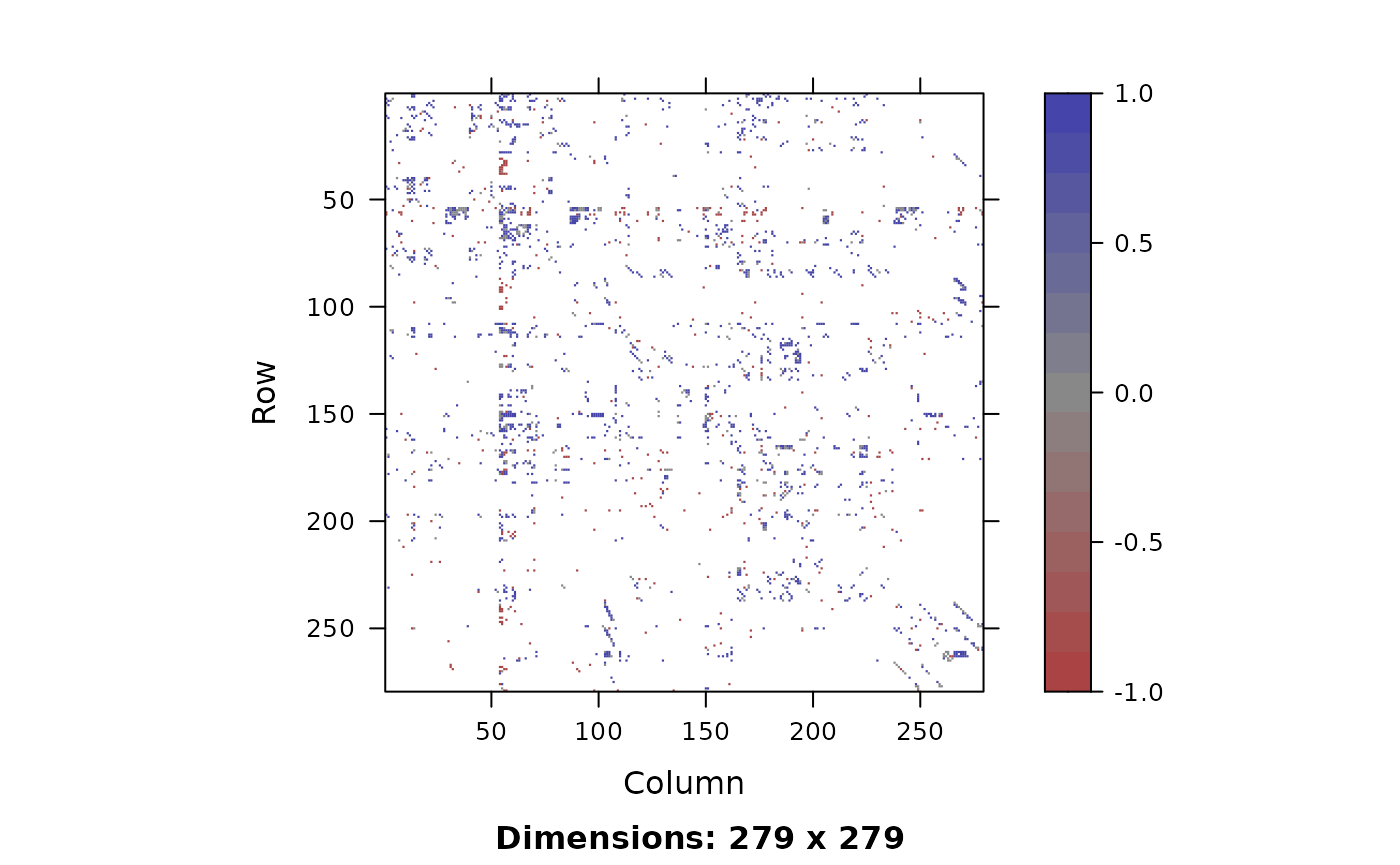
Edge discrepancies for the matched graphs with the true correspondence (left) and FW algorithm starting at the true correspondence (right). Green pixels represents an edge in the chemical graph while no edge in the electrical graph. Red pixels represent only an edge in the electrical graph. Grey pixels represent there is an edge in both graphs and white represents no edge in both graphs.
nv <- nrow(C1)
id_match <- graphMatch(data.frame(corr_A = 1:nv, corr_B = 1:nv), nv)
i_sum <- summary(id_match, C.Elegans[[1]], C.Elegans[[2]])
m_sum <- summary(match, C.Elegans[[1]], C.Elegans[[2]], id_match)
i_emi <- i_sum$edge_match_info
m_emi <- m_sum$edge_match_infoMatching the C. Elegans networks is a challenging task. Figures @ref(fig:C-Elegans-edge) depict the edge discrepancies of two networks under the true alignment and the matching correspondence using FW algorithm initialized at the true alignment. The alignment found using FW is not the identity with 124 out of 279 nodes correctly matched and improves upon the identity in terms of the number of edge discrepancies. For the true alignment, there are 116 edge errors and 1380 common edges while the alignment yielded by FW initialized at the true correspondence has 267.5 edge errors and 1078 common edges. Hence, this graph matching object does not have a solution at the true alignment. One can try to use other objective functions to enhance the matching result, however we do not investigate this here. Overall, while most performance measures are poor, our results illustrate the spectrum of challenges for graph matching.
Soft matching: MAP@3
Considering matching C. Elegans graphs is quite challenging, let’s assume 20 pairs of vertices are known as seeds, which are chosen at random. Accordingly, we generate a similarity matrix with 1’s corresponding to seeds, and the rest being barycenter.
seeds <- sample(nrow(C1), 20)
sim <- init_start(start = "bari", nns = nrow(C1), soft_seeds = seeds)In addition to one-on-one matching, we will also conduct soft matching, which is to find three most promising matches to each non-seed vertex. We achieve the goal of soft matching by finding the top 3 largest values in each row of the doubly stochastic matrix from the last iteration of Frank Wolfe methodology with indefinite relaxation and PATH algorithm, as well as the normalized matrix from the last iteration of the power method for IsoRank algorithm. To evaluate the matching performance, we will look at both matching precision: \(precision=\frac{1}{n_m-s}\sum_{i\in V_m\setminus S}P_{ii}\), and Mean Average Precision @ 3 (MAP@ 3):\(MAP@3 = \frac{1}{n_m-s}\sum_{i\in V_m\setminus S}1_{\{i\in T_i\}}\), where \(T_i\) is the set of 3 most promising matches to node \(i\).
set.seed(123)
m_FW <- gm(A = C1, B = C2, seeds = seeds,
similarity = sim, method = "indefinite",
start = "bari", max_iter = 100)
m_PATH <- gm(A = C1, B = C2, seeds = seeds,
similarity = NULL, method = "PATH",
epsilon = 1, tol = 1e-05)
m_Iso <- gm(A = C1, B = C2, seeds = seeds,
similarity = as.matrix(sim), method = "IsoRank",
max_iter = 50, lap_method = "LAP")
match_eval <- function(match){
precision <- mean(match$corr_A == match$corr_B)
order <- apply(match$soft, MARGIN = 1, FUN = order, decreasing = TRUE)
top3 <- t(order[1:3,]) - 1:ncol(order)
MAP3 <- mean(apply(top3, MARGIN = 1, FUN = function(v){0 %in% v}))
round(data.frame(precision, MAP3),4)
}
sapply(list(m_FW, m_PATH, m_Iso), match_eval) %>%
knitr::kable(col.names = c("Frank Wolfe", "PATH", "IsoRank"),
booktabs = TRUE, digits = 2)| Frank Wolfe | PATH | IsoRank | |
|---|---|---|---|
| precision | 0.0896 | 0.086 | 0.0789 |
| MAP3 | 0.0968 | 0.1111 | 0.0824 |
MAP@ 3 is slightly higher than precision for each method. Soft matching provides an alternative way of matching by generating a set of promising matching candidates.
Example: Britain Transportation Network
To demonstrate matching multi-layer networks-layers, we consider two graphs derived from the Britain Transportation network (Riccardo and Marc (2015)). The network reflects the transportation connections in the UK, with five layers representing ferry, rail, metro, coach, and bus. A smaller template graph was constructed based on a random walk starting from a randomly chosen hub node, a node that has connections in all the layers. The template graph has 53 nodes and 56 connections in total and is an induced subgraph of the original graph.
Additionally, based on filter methods from , the authors of that paper also provided a list of candidate matches for each template node, where the true correspondence is guaranteed to be among the candidates. The number of candidates ranges from 3 to 1059 at most, with an average of 241 candidates for each template vertex. Thus, we made an induced subgraph from the transportation network with only candidates, which gave us the world graph with 2075 vertices and 8368 connections.
tm <- Transportation[[1]]
cm <- Transportation[[2]]
candidate <- Transportation[[3]]Figure \(\ref{Fig:trans_net}\) visualizes the transportation connections for the induced subgraphs, where means of transportation are represented by different colors. Note that all edges in the template are common edges shared by two graphs, where 40%, 24.1%, 37.5%, 31.7% and 25.6% of edges in the world graph are in template for each layer. All graphs are unweighted, directed, and do not have self-loops. Tables @ref(tab:edge-summary-trans) further displays an overview and edge summary regarding each layer of the Britain Transportation Network. A true correspondence exists for each template vertex in the world graph, our goal is to locate each template vertex in the Britain Transportation network by matching two multi-layer graphs with different number of vertices.
| Layer | # Nodes | # Edges | Correlation | Common | Missing | Extra |
|---|---|---|---|---|---|---|
| Ferry | 53 / 2075 | 10 / 42 | 0.63 | 10 | 0 | 15 |
| Rail | 53 / 2075 | 14 / 4185 | 0.49 | 14 | 0 | 44 |
| Metro | 53 / 2075 | 9 / 445 | 0.61 | 9 | 0 | 15 |
| Coach | 53 / 2075 | 13 / 2818 | 0.56 | 13 | 0 | 28 |
| Bus | 53 / 2075 | 10 / 878 | 0.50 | 10 | 0 | 29 |
Visualization of the template graph (left) and the world graph (right) with corresponding vertices, both derived from the Britain Transportation network with five layers: ferry, rail, metro, coach, and bus. Edges represent transportation transactions and each color indicates a different means of transportation from a different layer of network.
Based on the candidates, we specify a start matrix that is row-stochastic which can be used for the argument in the graph matching function for FW methodology. For each row node, its value is either zero or the inverse of the number of candidates for that node. To ensure that template nodes only get matched to candidates, we constructed a similarity score matrix by taking the start matrix \(\times 10^5\), so that a high similarity score is assigned to all the template-candidate pairs.
Then we match the template graph with the world graph using Percolation algorithm. The template graph stored in and world graph are lists of 5 matrices of dimensions 53 and 2075 respectively. Since we have no information on seeds, we assign to the argument, the Percolation algorithm will initialize the mark matrix using prior information in the similarity score matrix.
match <- gm(A = tm, B = cm, similarity = similarity,
method = "percolation", r = 4)
summary(match, tm, cm)## Call: gm(A = tm, B = cm, similarity = similarity, method = "percolation",
## r = 4)
##
## # Matches: 53, # Seeds: 0, # Vertices: 53, 2075
## layer 1 2 3 4 5
## common_edges 10.0 13.0 9.0 11.0 10.0
## missing_edges 0.0 1.0 0.0 2.0 0.0
## extra_edges 22.0 36.0 21.0 24.0 35.0
## fnorm 4.7 6.1 4.6 5.1 5.9The function outputs edge statistics and objective function values for each layer separately. To further improve matching performance, one can replicate all the analysis in the first example on Enron dataset, such as using the centering scheme and adaptive seeds. Finally, one can refer to the match report to compare matching performance and pick the best one.
Conclusions
In this work, we detail the methods and usage of the R package
iGraphMatch for finding and assessing an alignment between
the vertex sets of two edge-correlated graphs. The package implements
common steps for the analysis of graph matching: seamless matching of
generalized graphs, evaluation of matching performance, and
visualization. For each of the graph matching methodologies, we provide
versatile options for the form of input graphs and the specification of
available prior information. Through the discussion in section \(\ref{sec:example}\), we demonstrate the
broad functionality and flexibility of the package by analyzing diverse
graph matching problems on real data step by step. The package also
provides tools for simulating correlated graphs which can be used in the
development and enhancement of graph matching methods.
Methods for graph matching are still under active development. We plan to include other novel methods as the field continues to develop. In the short term we are looking to introduce a suite of additional matching methods that have recently been proposed in the literature.
One of the biggest challenges for graph matching is evaluating the quality of a match, especially at the vertex level. This has received minimal attention in the previous literature. We provide measures of goodness of matching on the vertex level and demonstrate their effectiveness empirically. These baseline methods implement a permutation testing framework for assessing matches that can be readily extended to other metrics.
The primary authors for the package are Vince Lyzinski, Zihuan Qiao, and Daniel Sussman. Joshua Agterberg, Lujia Wang, and Yixin Kong also provided important contributions. We also want to thank all of our users, especially Youngser Park, for their feedback and patience as we continue to develop the package.
This work was supported in part by grants from DARPA (FA8750-20-2-1001 and FA8750-18-0035) and from MIT Lincoln Labs.